[Project] "시간대 별 지하철 승하차 예측" 프로젝트 회고
정보
📢 현재 포스팅은 2023년 1학기에 진행한 개인 프로젝트에 대한 회고입니다!
🎨 프로젝트 개요
저는 자차를 보유하고 있지 않기에 이동 간에 주로 지하철을 자주 이용합니다.
당시에는 대학교와 집 간의 통학 거리가 멀어 왕복 약 4시간의 거리를 이동했습니다.
사람이 많을지 적을지를 사전에 예측하면 좋지 않을까를 생각한 것이 프로젝트의 시작입니다.
쾌적한 이용 시간을 미리 확인한다면 실제 이동 시간도 맞추면 좋겠다는 생각에 기획하게 됐습니다.
무언가 프로그램의 완성품보다는 데이터 분석과 데이터 예측에 초점을 맞춘 프로젝트입니다.
⌛ 개발 기간
당시 급하게 프로젝트를 기획하고 제작했기에 기간은 아래와 같이 굉장히 짧습니다.
- 총 기간: 2023.06.05 ~ 2023.06.06 (2일)
💻 기술 스택
🔧 언어
🦴 프레임워크
🍨 데이터셋 수집
최초 데이터셋은 서울교통공사에서 제공되는 페이지에서 2015년부터의 월 별 현황을 다운로드했습니다.
해당 데이터는 월 별로 수집된 데이터이므로 일 별, 시간대 별로 예측하기에는 어려움이 존재하였습니다.
이에 추가 데이터셋 수집이 필요했고 data.go.kr 페이지를 활용하여 데이터를 수집할 수 있었습니다.
프로젝트에서 사용한 데이터는 서울교통공사에 역별 일별 시간대별 승하차 인원 데이터를 이용합니다.
해당 데이터는 여기 페이지로 이동할 경우 데이터를 다운로드 받으실 수 있으니 참고 부탁드립니다.
❄️ 데이터셋 분석
데이터셋을 분석하는 과정은 각각의 데이터 별로 수행하였습니다.
월별 데이터를 위주로 분석하여 이를 시각화하는 작업을 수행했습니다.
✨ 데이터 속성 확인
데이터셋에서 제공되는 속성을 확인하였고 데이터의 사용 여부도 구분하였습니다.
| Column 명 | 설명 | 사용 여부 |
|---|---|---|
| 사용월 | 대상 기간 | Y |
| 호선명 | 대상 지하철 호선 | Y |
| 지하철역 | 대상 지하철 역 | Y |
| 04시-05시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 04시-05시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 05시-06시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 05시-06시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 06시-07시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 06시-07시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 07시-08시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 07시-08시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 08시-09시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 08시-09시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 09시-10시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 09시-10시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 10시-11시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 10시-11시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 11시-12시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 11시-12시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 12시-13시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 12시-13시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 13시-14시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 13시-14시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 14시-15시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 14시-15시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 15시-16시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 15시-16시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 16시-17시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 16시-17시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 17시-18시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 17시-18시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 18시-19시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 18시-19시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 19시-20시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 19시-20시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 20시-21시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 20시-21시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 21시-22시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 21시-22시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 22시-23시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 22시-23시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 23시-24시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 23시-24시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 00시-01시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 00시-01시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 01시-02시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 01시-02시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 02시-03시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 02시-03시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 03시-04시 승차인원 | 해당 시간대의 총 승차인원 | Y |
| 03시-04시 하차인원 | 해당 시간대의 총 하차인원 | Y |
| 작업일자 | 데이터를 삽입한 일자 | N |
작업일자의 경우 데이터를 삽입, 그러니까 제공하기 시작한 일자이므로 제외했습니다.
😏 승/하차 데이터 분석
Python을 이용하여 데이터 분석을 수행했고 시간대 별 호선 별 승차자를 확인하였습니다.
승차 데이터 확인을 위해 in_station 변수를 만들고 속성명에 승차가 있는 경우 추가했습니다.
# 승차 데이터 확인
in_station = station_data.columns.tolist()[:3]
for a in station_data.columns.tolist():
if a.find('승차') != -1:
in_station.append(a)
in_station_df = station_data[in_station]
in_station_df.head()시간대 별 호선 별 승차자 데이터가 필요하므로 사용월과 지하철역에 대한 속성은 삭제하였습니다.
삭제 이후 호선명 속성을 이용해 Group By 진행하여 데이터를 확인할 수 있도록 했습니다.
# 승차 데이터 인원 통합 진행 간 불필요한 데이터 삭제 (지하철역, 사용월)
in_station_sorting = in_station_df.drop(['사용월', '지하철역'],axis=1)
# 승차 데이터 호선 별 전체 인원 통합
in_station_sorting = in_station_sorting.groupby(['호선명']).sum()
in_station_sorting데이터의 스타일을 Background Gradient 형식으로하여 Hitmap 형식으로 출력합니다.
아래와 같이 2호선의 경우 전체적인 시간대에서 많은 인원이 탑승한다는 것을 파악할 수 있습니다.
# 가장 승차자가 많은 지하철 호선 계산
in_station_sorting.style.background_gradient()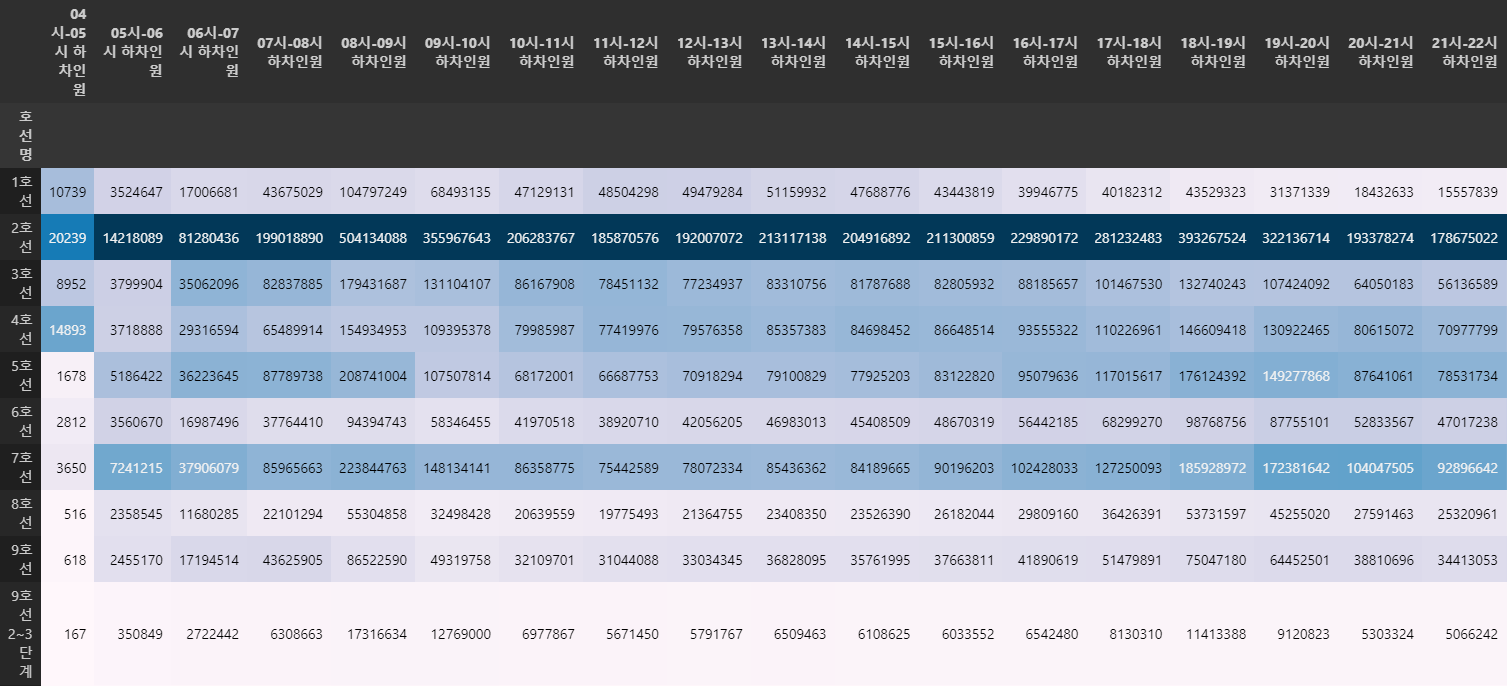
이번에는 호선명과 지하철역 별로 사용자의 밀집 수를 확인하고 싶었고 사용월 속성은 불필요하여 삭제,
그리고 호선명과 지하철역 속성의 경우 Group By를 통해 데이터를 통합하여 변수에 저장하였습니다.
# 그렇다면 각 호선의 역 별 사용자 수를 한번 확인해보고자 함
# 승차 데이터 인원 통합 진행 간 불필요한 데이터 삭제 (사용월)
in_station_sorting = in_station_df.drop(['사용월'],axis=1)
# 승차 데이터 호선 별 전체 인원 통합
in_station_sorting = in_station_sorting.groupby(['호선명', '지하철역']).sum()
in_station_sorting이번에는 2호선을 기준으로 Background Gradient 형식으로 데이터를 출력하였습니다.
확인 시 특정 시간대를 제외하면 강남역에 높은 비중이 있는 것을 확인할 수 있습니다.
# 2호선 내 가장 많은 인원이 사용하는 역을 확인
in_station_sorting.loc['2호선'].style.background_gradient()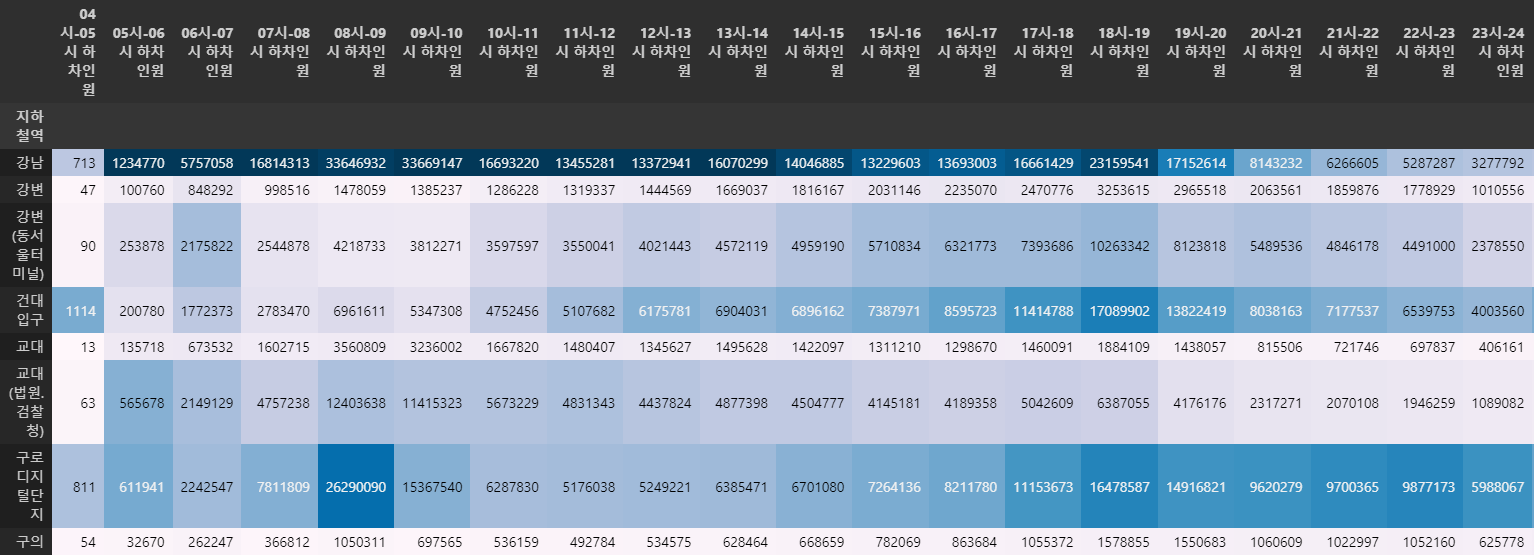
그렇다면 2호선 기준 시간 불문하고 가장 많은 탑승자를 보유한 곳은 어딘지 보았습니다.
확인 시 이전 지표에서 보였던 사항과 같이 가장 탑승자가 많은 역은 강남역인 것으로 확인됩니다.
# 그렇다면 2호선 내에서 시간을 불문하고 가장 많은 사람이 승차하는 역은 어디인지 계산해본다
# 승차 데이터 인원 통합 진행 간 불필요한 데이터 삭제 (사용월)
in_station_sorting = in_station_df.drop(['사용월'],axis=1)
# 승차 데이터 호선 별 전체 인원 통합
in_station_sorting['총 탑승자'] = in_station_sorting.sum(axis=1)
in_station_sorting = in_station_sorting.groupby(['호선명', '지하철역']).sum()
in_station_sorting.loc['2호선', '총 탑승자'].to_frame().style.background_gradient()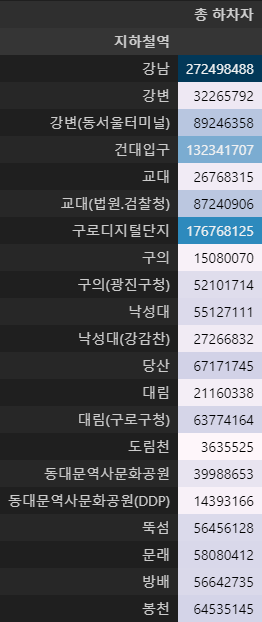
이러한 탑승자의 데이터를 막대 그래프로 시각화할 경우 아래와 같이 확인됩니다.
# 총 탑승자에 대한 데이터를 시각화하여 바 형 그래프로 표기
in_station_sorting.loc['2호선', '총 탑승자'].to_frame().plot(kind='bar')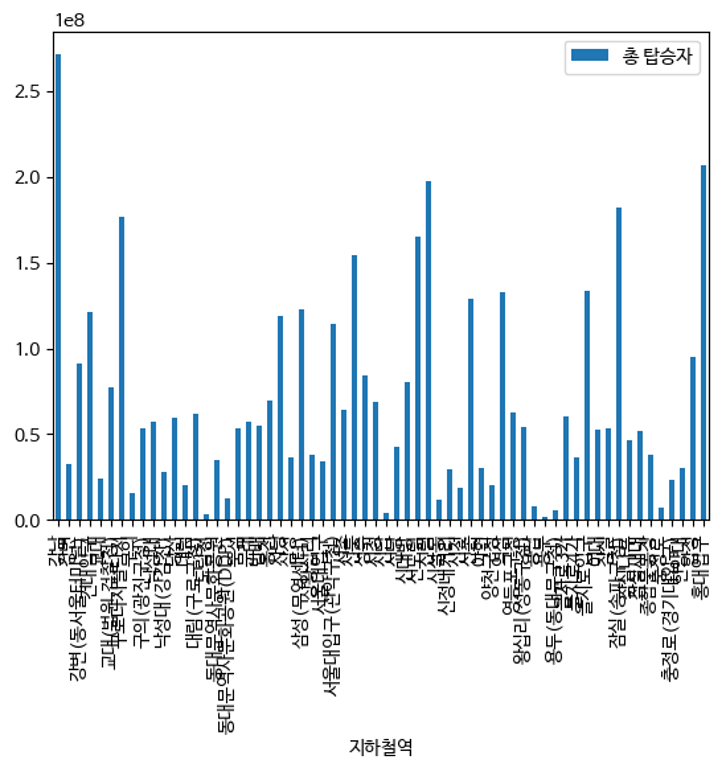
🦾 기계 학습
월 별 데이터를 가지고 데이터를 확인하는 것은 좋았으나 학습에 이용하기에는 무리가 있습니다.
이에 따라 일 별 데이터를 이용하여 데이터를 가공하고 기계학습을 통해 추론해보겠습니다.
❄️ 데이터 속성 확인
일 별 데이터에서 불필요한 데이터가 존재하는지 확인을 위해 각 속성을 표로 정리해봤습니다.
| Column 명 | 설명 | 사용 여부 |
|---|---|---|
| 연번 | 순번 | N |
| 수송일자 | 이용자 수송 일자 | Y |
| 호선 | 대상 지하철 호선 | Y |
| 고유역번호(외부역코드) | 대상 지하철 역에 고유 번호 | Y |
| 역명 | 대상 지하철 역명 | N |
| 승하차구분 | 승/하차 여부 표기 | Y |
| 06시이전 | 대상 시간대의 승/하차 인원 | Y |
| 06-07시간대 | 대상 시간대의 승/하차 인원 | Y |
| 07-08시간대 | 대상 시간대의 승/하차 인원 | Y |
| 08-09시간대 | 대상 시간대의 승/하차 인원 | Y |
| 09-10시간대 | 대상 시간대의 승/하차 인원 | Y |
| 10-11시간대 | 대상 시간대의 승/하차 인원 | Y |
| 11-12시간대 | 대상 시간대의 승/하차 인원 | Y |
| 12-13시간대 | 대상 시간대의 승/하차 인원 | Y |
| 13-14시간대 | 대상 시간대의 승/하차 인원 | Y |
| 14-15시간대 | 대상 시간대의 승/하차 인원 | Y |
| 15-16시간대 | 대상 시간대의 승/하차 인원 | Y |
| 16-17시간대 | 대상 시간대의 승/하차 인원 | Y |
| 17-18시간대 | 대상 시간대의 승/하차 인원 | Y |
| 18-19시간대 | 대상 시간대의 승/하차 인원 | Y |
| 19-20시간대 | 대상 시간대의 승/하차 인원 | Y |
| 20-21시간대 | 대상 시간대의 승/하차 인원 | Y |
| 21-22시간대 | 대상 시간대의 승/하차 인원 | Y |
| 22-23시간대 | 대상 시간대의 승/하차 인원 | Y |
| 23-24시간대 | 대상 시간대의 승/하차 인원 | Y |
| 24시이후 | 대상 시간대의 승/하차 인원 | Y |
데이터 속성 중 연번의 경우 단순 순번이므로 불필요, 역명은 고유역번호로 대체됩니다.
이에 두 데이터 속성은 삭제하고 나머지 데이터셋을 이용하여 학습을 수행하려고 합니다.
🏭 데이터 전처리
현재 기계학습을 통해서는 가장 탑승자가 많았던 2호선을 기준으로 데이터를 분리하였습니다.
day_station_data = day_station_data[day_station_data['호선'] == 2]예측에 사용될 때 중요한 요소는 결측치와 이상치를 확인하는 작업이라고 볼 수 있습니다.이상치는 CSV 파일 양상으로는 별다른 내용이 없어 결측치를 아래와 같이 확인했습니다.
확인 시에는 24시이후 속성에 결측치가 15,100건이 존재하는 것으로 확인되고 있습니다.
print(pd.isnull(day_station_data).sum())연번 0
수송일자 0
호선 0
고유역번호(외부역코드) 0
역명 0
승하차구분 0
06시이전 0
06-07시간대 0
07-08시간대 0
08-09시간대 0
09-10시간대 0
10-11시간대 0
11-12시간대 0
12-13시간대 0
13-14시간대 0
14-15시간대 0
15-16시간대 0
16-17시간대 0
17-18시간대 0
18-19시간대 0
19-20시간대 0
20-21시간대 0
21-22시간대 0
22-23시간대 0
23-24시간대 0
24시이후 15100
dtype: int64이는 운행 시간 종료로 인한 것으로 fillna 함수를 이용하여 0으로 채우고 확인해보면
정상적으로 모든 속성의 결측치가 사라진 것을 확인해보실 수 있습니다.
day_station_data.fillna(0, inplace=True)
print(pd.isnull(day_station_data).sum())연번 0
수송일자 0
호선 0
고유역번호(외부역코드) 0
역명 0
승하차구분 0
06시이전 0
06-07시간대 0
07-08시간대 0
08-09시간대 0
09-10시간대 0
10-11시간대 0
11-12시간대 0
12-13시간대 0
13-14시간대 0
14-15시간대 0
15-16시간대 0
16-17시간대 0
17-18시간대 0
18-19시간대 0
19-20시간대 0
20-21시간대 0
21-22시간대 0
22-23시간대 0
23-24시간대 0
24시이후 0
dtype: int64이제 데이터에서 불필요한 속성을 아래와 같이 선정하여 삭제하도록 하겠습니다.
호선: 2호선만 구분하여 데이터 분할할 때 사용했으므로 삭제합니다.연번: 데이터의 순서로 구분이 불가하므로 삭제합니다.역명: 다른 구분 속성이 존재하므로 삭제합니다.
day_station_data.drop(['연번', '역명', '호선'], axis=1, inplace=True)
day_station_data.reset_index(drop=True, inplace=True)데이터 중 문자열로 구성된 승하차 구분 속성을 숫자 형태의 데이터로 변경합니다.
mapping_type = {'승차': 1, '하차': 2}
day_station_data['승하차구분'] = day_station_data['승하차구분'].apply(lambda x : mapping_type[x])이제 데이터를 학습시킬 수 있지만 저는 여기서 중요한 요소 중 하나인 공휴일 데이터도 추출했습니다.
공휴일 정보는 한국천문연구원 특일 정보를 이용해 추출한 것으로 해당 데이터를 병합해주었습니다.
holidays_data = pd.read_csv('2022년 공휴일 데이터.csv')
holidays_data['일자'] = pd.to_datetime(holidays_data['일자'].astype('str'), infer_datetime_format=True).dt.strftime("%Y-%m-%d")추출된 데이터 중 isHoliday 속성은 불필요하므로 아래와 같이 삭제해주었습니다.
holidays_data.drop('isHoliday', axis=1, inplace=True)수송일자 속성과 공휴일 데이터의 일자를 비교하여 동일한 경우 1이라는 데이터를 추가합니다.
이후 1이 추가되지 못한 모든 데이터는 0을 채워주어 모든 데이터가 결측되지 않도록 합니다.
day_station_data.loc[day_station_data['수송일자'].isin(holidays_data['일자']), '공휴일'] = 1
day_station_data.fillna(0, inplace=True)마지막으로 weekday 속성을 만들어 데이터를 추가하도록 합니다.
day_station_data['weekday'] = pd.to_datetime(day_station_data['수송일자'].astype('str'), infer_datetime_format=True).dt.weekday📖 데이터 학습
데이터 학습을 하여 예측을 통해 이후 데이터를 예측해야할 시간입니다.
우선 데이터를 속성과 결과로 나눈 뒤 데이터를 8:2로 분리하였습니다.
# 이제 데이터는 어느정도 준비됐다고 판단된다 이를 이제 예측할 수 있도록 데이터를 학습시키고 예측해보겠다.
from sklearn.model_selection import train_test_split
# '고유역번호(외부역코드)', '승하차구분', '공휴일', 'weekday'
X = day_station_data.loc[:, ['고유역번호(외부역코드)', '승하차구분', '공휴일', 'weekday']]
# 06시 이전~24시 이후
y = day_station_data.iloc[:, 3:-2]
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)학습 간에는 알고리즘 선택이 필요한데 선형 회귀부터 굉장히 다양하게 존재합니다.
제 경우는 앙상블 알고리즘 중 랜덤포레스트의 회귀 버전을 선택하였습니다.
또한 하이퍼 파라미터라 불리는 요소를 임시로 값을 주고 학습을 진행했습니다.
n_estimators: 생성할 트리의 개수 (앙상블 알고리즘이므로 여러 개를 생성하고 나은 것을 선택)max_depth: 트리의 최대 깊이random_state: 시드
# 랜덤 포레스트 회귀 관련 라이브러리 import 진행
from sklearn.ensemble import RandomForestRegressor
clf = RandomForestRegressor(n_estimators=30, max_depth=5, random_state=0)
clf.fit(X_train, y_train)이제 학습된 모델을 이용하여 미리 나눠둔 테스트 데이터를 이용해 예측합니다.
# 예측
predict = clf.predict(X_test)
predict학습된 모델의 성능 확인을 위해 예측된 데이터를 이용해 점수를 계산했습니다.
R2 Score는 0~1 사이의 값으로 1에 가까울수록 데이터를 잘 설명하고 있는 것인데,
여기서는 0.43 그러니 43% 정도에 대해서만 잘 설명하고 있다는 것을 확인할 수 있습니다.
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
r2 = r2_score(y_test, predict)
mse = mean_squared_error(y_test, predict)
mae = mean_absolute_error(y_test, predict)
rmse = np.sqrt(mse)
print(r2, mse, mae, rmse)0.43064800805755354 1133001.3136080105 583.4148917419377 1064.4253443093182예측 성능을 높이기 위해 적절한 값을 찾을 수 있도록 파라미터를 변경하도록 합니다.
제 경우 n_estimators를 31~70, max_depth를 6~15로 변경하여 학습률을 계산했습니다.
도출된 사항을 확인 시 n_estimators는 64, max_depth는 15인게 가장 성능이 좋았습니다.
다만, 걱정되는 것은 max_depth가 높은 경우 과대적합에 빠질 수 있다는 것입니다.
# 해당 작업에 대해 조금 더 정확도를 올려보기 위해 시도
# n_estimators 31~70까지, max_depth를 6~15까지의 데이터를 관찰,
# 가장 높은 R2 Score를 갖는 하이퍼 파라미터를 마지막에 출력
good_n_estimators = 0
good_depth = 0
good_score = 0
print ("Estimator Max Depth R2 MSE MAE RMSE")
for n_estimators in range(31, 71):
for max_depth in range(6, 16):
clf = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth, random_state=0)
clf.fit(X_train, y_train)
predict = clf.predict(X_test)
r2 = r2_score(y_test, predict)
mse = mean_squared_error(y_test, predict)
mae = mean_absolute_error(y_test, predict)
rmse = np.sqrt(mse)
print(n_estimators, " ", max_depth, " ", r2, " ", mse, " ", mae, " ", rmse)
print(good_n_estimators, good_depth, good_score)Estimator Max Depth R2 MSE MAE RMSE
31 6 0.5472373289907819 803385.0433594751 507.7489655354075 896.3174902675252
31 7 0.6743412245490967 521630.3563353627 396.3530198399759 722.2398191289114
31 8 0.7583191233120332 363115.05645392154 305.0949887355562 602.5902890471448
31 9 0.8053625873926953 270449.927521984 261.5662613519538 520.0480050168292
31 10 0.8354556008577818 201169.2016300668 229.1272788868442 448.5188977401808
31 11 0.8743741066499149 130451.81817994926 185.96544244168925 361.18114316773136
31 12 0.8932927987710751 101679.07150709162 158.77751035118936 318.87155957703663
...
64 15 0.9099357176290036이렇게 최종적으로 모델을 만들고 이의 성능까지 측정해본 것이 프로젝트였습니다.
📚 관련 코드
제가 수행해서 만들어둔 코드는 GitHub 저장소로 게시해두었습니다.
혹시나 프로젝트에 도움이 되실 것 같다면 참고하시면 좋을 것 같습니다.
😅 아쉬운 점
당시에는 대학교를 편입한 첫 학기고 인공지능에 대해 처음 공부했습니다.
그래서 미숙함과 인공지능에 대한 지식이 지금보다도 많이 부족했던 시기였습니다.
다양한 알고리즘을 이용하여 비교해보지 못한 것도 너무 아쉬운 부분이라 생각되고,
더 많은 데이터를 수집하여 진행하지 못한 것도 하나의 아쉬움으로 남고 있습니다.
다음에는 최근에 더 발전된 회귀 알고리즘 등을 이용해보고자 하는 생각이 있고,교차검증 등을 통해 데이터의 검증을 더욱 많이 해보는 것도 하나의 생각입니다.
😏 향후 계획
이러한 경험을 통해 현재 클라우드 서비스에도 반영을 해보고자 하는 사항이 있습니다.
우선 비용 예측으로 이부분은 이전에도 회귀로 많이 진행했기에 충분히 가능할거라 봅니다.
또 한 가지는 모니터링 요소로 수치화된 CPU, Memory, Disk 등 자원의 상관 관계를 찾아
이를 학습하고 다음 수치를 미리 예측하여 사전에 장애 등을 대비하는 것을 생각 중입니다.
해당 프로젝트는 진행을 위해 많은 데이터가 필요하고 현재 예제 데이터를 수집 중입니다.
시간이 될진 모르겠지만 여유가 된다면 이러한 데이터를 기반으로 프로젝트를 하고 싶습니다.
제가 인공지능을 처음으로 접하면서 진행했던 프로젝트로 아쉬움이 많이 남습니다.
현재 4학년 2학기이지만 많이 부족하고 그때를 돌아보면 더 많이 부족했던 것 같습니다.
앞으로 더욱 발전하기 위해 노력해야겠다는 생각도 들고 다양한 도전이 필요한 것 같네요.
정말 긴 포스팅 끝까지 읽어주셔서 감사드립니다. 😎