[Project] "클라우드 비용 예측" 프로젝트 회고
정보
📢 현재 포스팅은 2024년 2학기에 진행한 개인 프로젝트에 대한 회고입니다.
🎨 프로젝트 개요
저는 클라우드 서비스를 제공하는 회사에 근무 중이며 비용에 대한 이슈를 자주 접하게 됩니다.
가끔 생각나는 내용으로 비용의 추이를 미리 예측할 수 있다면 굉장히 좋을텐데라는 고안을 하였는데,
이런 비용 예측 내용을 차트 형태로 만들어 실제 비용과 비교해보면 어떨까라는 생각도 하게 됐습니다.
딥러닝에 대해 공부하고 있는 입장으로 어떻게 구현할까란 고민을 하였고 프로젝트를 기획했습니다.
⌛ 개발 기간
빠르게 프로젝트를 수행하고 마무리하기 위해서 기간은 학습 시간까지 포함하여 짧게 잡아보았습니다.
- 총 기간: 2024.11.10 ~ 2024.11.20 (약 10일)
💻 기술 스택
🔧 언어
🦴 라이브러리
🍨 데이터셋 수집 및 분석
데이터셋의 경우 비용이다보니 민감 자료로 사내에서 사용하는 비용을 토대로 진행했습니다.
공개할 수는 없지만 데이터베이스에 저장된 내용을 CSV 형태로 변환하여 이용하였습니다.
기간으로는 2024.05~2024.10 기간 내의 비용 데이터를 수집하여 학습 간 사용했습니다.
✨ 데이터 속성 확인
데이터셋의 속성은 전처리 과정을 1차적으로 진행한 이후 아래와 같이 남아 이용하였습니다.
| 속성 명 | 설명 |
|---|---|
| BillDate | 수집 일자 |
| DemandTypeCodeName | 상품 대분류 |
| DemandTypeCodeDetailName | 상품 소분류 |
| UseAmount | 사용 비용 |
| DemandAmount | 청구 비용 |
| TotalDiscountAmount | 할인 비용 |
🪢 Meta Prophet을 이용한 예측
먼저 Meta에서 제공하는 Prophet이라는 시계열 데이터 예측을 이용해보았습니다.
📲 데이터 전처리
Prophet은 단변량 데이터를 분석하기에 설명변수(ds)와 예측변수(y)가 필요합니다.
위 사항을 맞추기 위해 데이터 변환이 필요하여 아래와 같이 작업을 수행하였습니다.
먼저 BillDate 속성 기준 데이터 통합 후 상품 분류에 대한 속성을 삭제했습니다.
import pandas as pd
df = pd.read_csv("파일명.csv")
df2 = df.groupby(['BillDate']).sum().reset_index()
df2 = df2.drop(['DemandTypeCodeName', 'DemandTypeCodeDetailName'], axis=1)데이터 중 BillDate 속성을 ds로, UseAmount를 y로 DataFrame을 생성했습니다.
data = pd.DataFrame()
data['ds'] = pd.to_datetime(df2['BillDate'], format='%Y%m%d')
data['y'] = df2['UseAmount']
data = data.reset_index()
data = data.drop('index', axis=1)합연산이 된 데이터이므로 y의 데이터에서 이전 데이터를 뺄셈 연산을 수행했습니다.
for i in range(len(data)-1, 0, -1):
if i == 0:
continue
elif data.loc[i]['ds'].day == 1:
continue
data.loc[i, 'y'] = (data.loc[i]['y'] - data.loc[i-1]['y'])이러한 데이터를 Matplot 라이브러리를 이용하여 시각화했고 아래와 같이 확인됩니다.
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
ax = data['y'].plot(title = "Cost", figsize =(12,4))
ax.set_ylabel('Cost')
plt.ticklabel_format(axis='y', style='plain')
plt.show()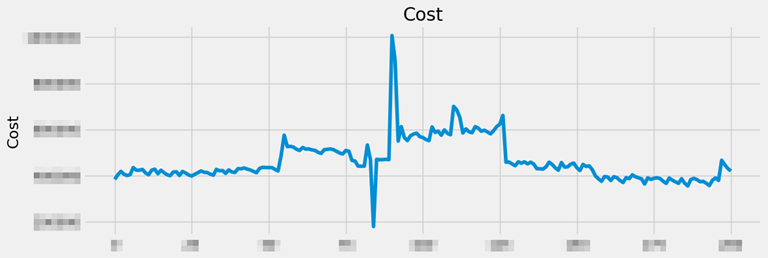
📈 모델 학습 및 확인
가공된 비용 데이터를 이용하여 Prophet 모델을 만들고 모델 학습을 수행합니다.
모델의 경우 주간의 경향성을 기반으로 확인하고 반영하도록 설정하였습니다.
model = Prophet(weekly_seasonality=True)
model.fit(data)학습된 모델을 이용하여 30일 이후의 비용을 예측을 진행한 뒤 결과를 확인하였습니다.
비용이 정기적일 경우 문제가 없겠지만 정기적이지 않기에 양상 반영에 어려움이 보입니다.
future = model.make_future_dataframe(periods=30, freq = 'D')
forecast = model.predict(future)
fig = model.plot(forecast, xlabel='Date', ylabel='Cost')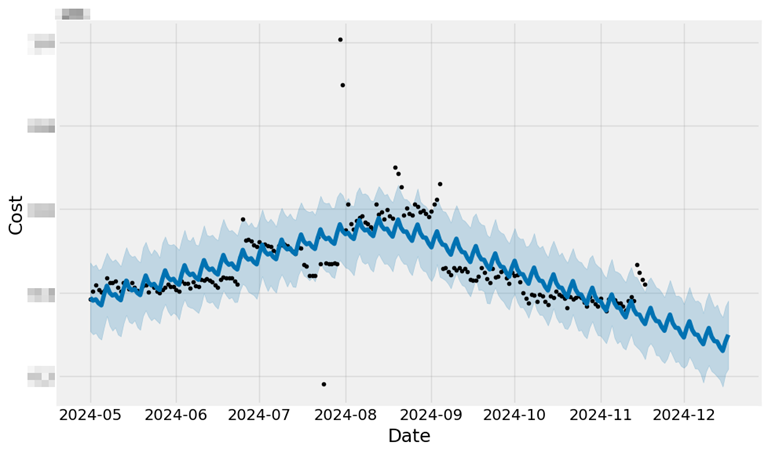
🎈 선형 회귀를 이용한 예측
앞선 Prophet 모델에서는 제대로된 경향성 반영을 못하는 모습을 확인할 수 있었습니다.
이러한 데이터 경향을 반영하기 위해 선형회귀 알고리즘을 이용해 예측 해보겠습니다.
📲 데이터 전처리
동일하게 BillDate 속성을 기준으로 데이터 통합 후 상품 분류 관련 속성을 삭제합니다.
df2 = df.groupby(['BillDate']).sum().reset_index()
df2 = df2.drop(['DemandTypeCodeName', 'DemandTypeCodeDetailName'], axis=1)기존과 같은 데이터를 이용하여 추론하기 위해 ds와 y를 나누어 두었습니다.
data = pd.DataFrame()
data['ds'] = pd.to_datetime(df2['BillDate'], format='%Y%m%d')
data['y'] = df2['UseAmount']
data = data.reset_index()
data = data.drop('index', axis=1)합연산이 된 데이터이므로 y의 데이터에서 이전 데이터를 뺄셈 연산을 수행했습니다.
for i in range(len(data)-1, 0, -1):
if i == 0:
continue
elif data.loc[i]['ds'].day == 1:
continue
data.loc[i, 'y'] = (data.loc[i]['y'] - data.loc[i-1]['y'])더 많은 속성을 가지고 학습하도록 28일 이전의 시계열 데이터를 같이 제공합니다.
다른 전처리가 완료되어 시간 데이터인 ds 속성을 Unix Timestamp로 변경했습니다.
for lag in range(1, 29): # 과거 28일 데이터 추가
data[f'lag_{lag}'] = data['y'].shift(lag)
data = data.dropna().reset_index(drop=True)
data['ds'] = data['ds'].apply(lambda x: int(x.timestamp()))
data.insert(len(data.columns)-1, 'y', data.pop('y'))
data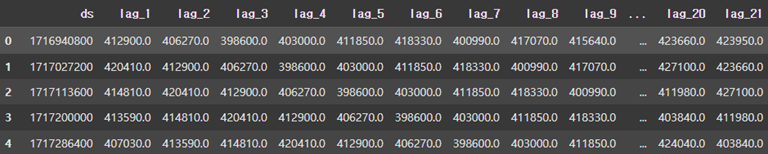
📈 모델 학습 및 확인
모델 학습과 테스트를 위해 학습 데이터와 테스트 데이터로 분할했습니다.테스트 데이터는 전체에서 최종 30개의 데이터로 선정하여 분할해두었습니다.
split_len = len(data)-30
X_train = data[:split_len].iloc[:, :len(df.columns)-2]
y_train = data[:split_len].loc[:, ['y']]
X_test = data[split_len:].iloc[:, :len(df.columns)-2]
y_test = data[split_len:].loc[:, ['y']]모델은 Scikit-learn을 이용하여 선형회귀 모델을 선언하여 이용하였습니다.모델의 학습 과정에서 사전 분리해둔 _train로 끝나는 데이터를 이용하게 됐습니다.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
model = LinearRegression()
model.fit(X_train, y_train)학습된 모델을 검증하기 위해 X_test 변수 데이터로 검증을 시도하였습니다.
lrm_predict = model.predict(X_test)검증된 데이터를 가진 변수를 이용하여 MSE와 MAE를 통해 손실을 확인했습니다.
(R2 Score도 이용하려 했지만 시계열 데이터엔 맞지 않아 제외했습니다.)
from sklearn.metrics import mean_squared_error, mean_absolute_error
mse = mean_squared_error(y_test, lrm_predict)
mae = mean_absolute_error(y_test, lrm_predict)
print(mse, mae)
# 출력: 645106360.0808157 20673.465840699464모델을 이용하여 예측한 결과와 테스트 데이터의 실제 결과를 비교해보았습니다.
제법 데이터의 경향을 잘 반영하여 데이터를 예측한 것을 확인하실 수 있습니다.
y_test = y_test.reset_index()
plt.clf()
plt.figure(figsize=(12, 8))
plt.plot(y_test['y'], color='red', label='Ideal Fit')
plt.plot(lrm_predict, color='blue')
plt.ticklabel_format(axis='y', style='plain')
plt.show()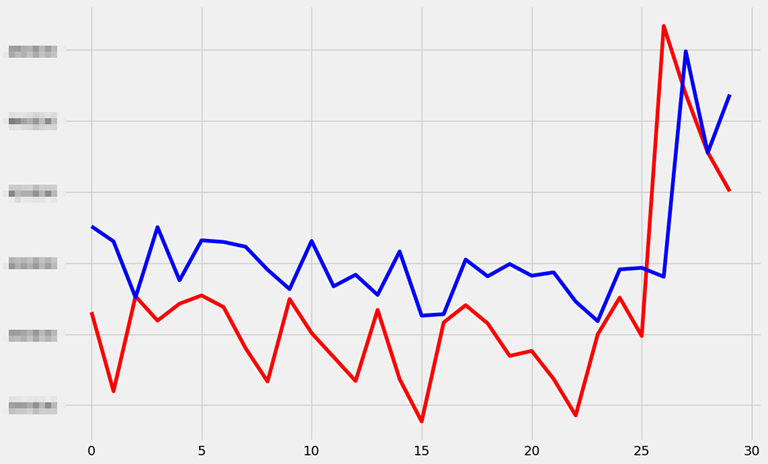
그렇다면 기존의 학습 데이터에 대해서는 어떤 양상을 보이는지 확인해보았습니다.학습 데이터에 대해서도 나름의 경향을 잘 따라가는 것을 확인 가능한 상태입니다.
lrm_predict_train = model.predict(X_train)
plt.clf()
plt.figure(figsize=(12, 8))
plt.plot(y_train['y'], color='red', label='Ideal Fit')
plt.plot(lrm_predict_train, color='blue')
plt.ticklabel_format(axis='y', style='plain')
plt.show()
💫 LSTM을 이용한 예측
선형 회귀를 이용한 예측에서도 나름의 경향은 잘 찾아가는 것을 확인하였습니다.LSTM을 이용하여 시계열 데이터를 예측한다면 어떻게 될지 확인해보았습니다.
우선 이번의 경우 선형 회귀 간 제작한 y 속성에 대해서만 사용하도록 하였습니다.
🎆 기본 설정
기본적으로 TensorFlow의 Seed를 고정하고 GPU 사용을 위해 설정을 수행합니다.
import os
import numpy as np
import tensorflow as tf
import random
seed = 42
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
os.environ["CUDA_VISIBLE_DEVICES"]="0"
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
tf.config.experimental.set_memory_growth(gpus[0], True)
except RuntimeError as e:
print(e)😀 관련 함수 생성
TensorFlow를 이용하여 기본 전처리된 데이터의 Sequence를 설정하는 부분과Batch, 은닉층의 Layer, Node 등을 설정할 수 있도록 함수를 만들었습니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.layers import LSTM, Dense, Dropout, Bidirectional
def create_sequences(data, seq_length):
x = []
y = []
for i in range(len(data) - seq_length):
x.append(data[i:i + seq_length])
y.append(data[i + seq_length])
return np.array(x), np.array(y)
def model_train(y, epoch=20, batch_size=32, seq_length=7, hidden_layer=1, hidden_node=1):
tf.random.set_seed(seed)
np.random.seed(seed)
random.seed(seed)
x_data, y_data = create_sequences(y, seq_length)
x_data = x_data.reshape((x_data.shape[0], x_data.shape[1], 1))
split = int(len(x_data)-30)
x_train, x_test = x_data[:split], x_data[split:]
y_train, y_test = y_data[:split], y_data[split:]
model = Sequential()
if hidden_layer > 1:
model.add(LSTM(hidden_node, activation='relu', return_sequences=True, input_shape=(seq_length, 1)))
for _ in range(1, hidden_layer-1):
model.add(LSTM(hidden_node, activation='relu', return_sequences=True))
model.add(LSTM(hidden_node, activation='relu', return_sequences=False))
else:
model.add(LSTM(hidden_node, activation='relu', return_sequences=False, input_shape=(seq_length, 1)))
if len(y_train.shape) > 1:
model.add(Dense(y_train.shape[1]))
else:
model.add(Dense(1))
learning_rate = 0.01
optimizer = Adam(learning_rate=learning_rate)
model.compile(optimizer=optimizer, loss='mean_squared_error')
history = model.fit(x_train, y_train, epochs=epoch, batch_size=batch_size, validation_data=(x_test, y_test), verbose=0)
return model, x_train, y_train, x_test, y_test, history진행 과정에서의 손실과 학습 이후의 손실을 확인할 수 있도록 함수를 생성합니다.
def history_view(history):
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss', linestyle='dashed')
plt.title(f'Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid()
plt.show()모델에 투입된 데이터와 예측 결과를 확인할 수 있도록 함수를 생성합니다.
def model_view(model, y_train, x_test, y_test):
y_pred = model.predict(x_test)
import matplotlib.pyplot as plt
original_range = range(len(y_train))
test_range = range(len(y_train), len(y_train) + len(y_test))
pred_range = range(len(y_train), len(y_train) + len(y_pred))
plt.figure(figsize=(12, 6))
plt.plot(original_range, y_train, label="Original Data (Labels)", alpha=0.5)
plt.plot(test_range, y_test, label="Test Data (Labels)", color='blue')
plt.plot(pred_range, y_pred, label="Predictions", color='red', linestyle='dashed')
plt.axvline(len(y_train), color='gray', linestyle='--', label="Train-Test Split")
plt.legend()
plt.title("Test Data and Predictions Appended After Original Data")
plt.xlabel("Index")
plt.ylabel("Class Label")
plt.show()📈 모델 학습 및 확인
최적의 모델을 찾을 수 있도록 위에서 생성한 함수 상 각 항목을 리스트로 전달합니다.
- 총 450가지의 경우의 수를 이용하여
모델을 비교하고 최적의 결과를 찾도록 했습니다.
best_epoch = 0
best_batch_size = 0
best_seq_length = 0
best_hidden_node = 0
best_hidden_layer = 0
best_score = -1
best_model = None
best_model_history = None
best_x_train = None
best_y_train = None
best_x_test = None
best_y_test = None
hidden_layers = [1, 2, 3, 4, 5, ]
hidden_nodes = [10, 20, 30, 40, 50, ]
epochs = [10, 20, 30, 40, 50, 60, ]
batch_sizes = [1, ]
seq_lengths = [7, 14, 28, ]
for epoch in epochs:
for batch_size in batch_sizes:
for seq_length in seq_lengths:
for hidden_layer in hidden_layers:
for hidden_node in hidden_nodes:
print("NOW:", epoch, batch_size, seq_length, hidden_layer, hidden_node)
model, x_train, y_train, x_test, y_test, history = model_train(y, epoch, batch_size, seq_length, hidden_layer, hidden_node)
score = model.evaluate(x_test, y_test, verbose=0)
print("NOW SCORE:", score)
if score < best_score or best_score == -1:
best_epoch = epoch
best_batch_size = batch_size
best_seq_length = seq_length
best_hidden_node = hidden_node
best_hidden_layer = hidden_layer
best_score = score
best_model = model
best_model_history = history
best_x_train = x_train
best_y_train = y_train
best_x_test = x_test
best_y_test = y_test
print("!!NOW BEST!!")
print(best_epoch, best_batch_size, best_seq_length, best_hidden_layer, best_hidden_node, best_score)
history_view(best_model_history)
model_view(best_model, best_y_train, best_x_test, best_y_test)
# 출력
# Epoch Batch Seq Layer Node MSE
# 40 1 7 1 50 381396512.0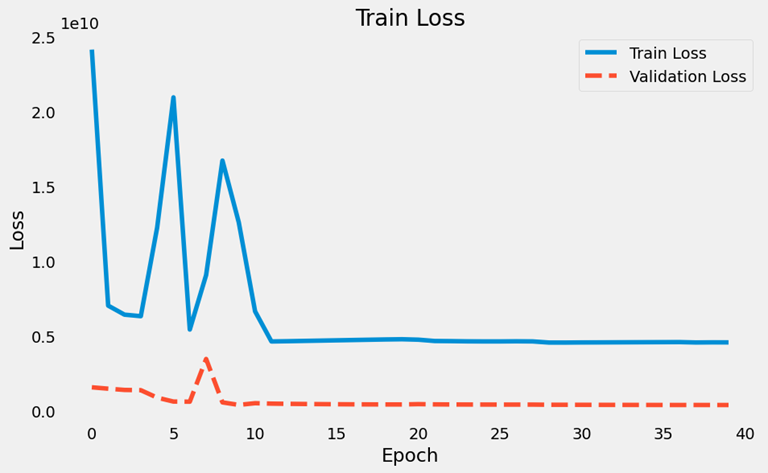
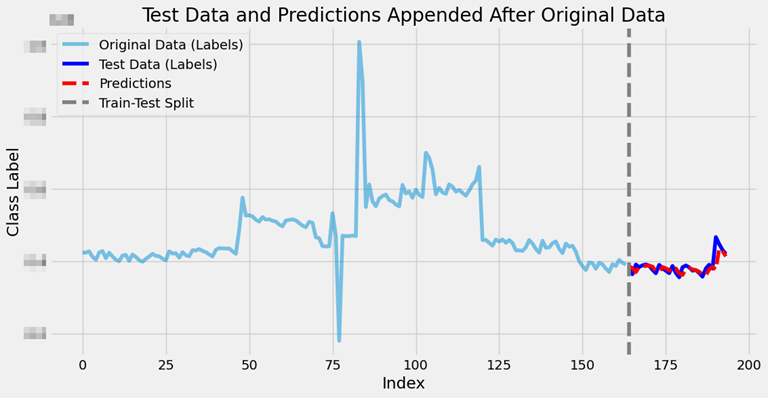
이를 실행하였을 때 최적의 값을 기존 선형회귀와의 MSE를 비교해보았습니다.
선형회귀: 645106360.0808157
MSE: 381396512.0테스트 데이터 검증만 수행했지만 데이터 예측 후 시각화하도록 함수를 생성했습니다.
def model_none_test_view(model, y_train, x_test, y_test, y_none_test):
y_pred = model.predict(x_test)
import matplotlib.pyplot as plt
original_range = range(len(y_train))
test_range = range(len(y_train), len(y_train) + len(y_test))
pred_range = range(len(y_train), len(y_train) + len(y_pred))
none_test_range = range(len(y_train) + len(y_pred), len(y_train) + len(y_pred) + len(y_none_test))
plt.figure(figsize=(12, 6))
plt.plot(original_range, y_train, label="Original Data (Labels)", alpha=0.5)
plt.plot(test_range, y_test, label="Test Data (Labels)", color='blue')
plt.plot(pred_range, y_pred, label="Predictions", color='red', linestyle='dashed')
plt.plot(none_test_range, y_none_test, label="Predictions None test", color='green', linestyle='dashed')
plt.axvline(len(y_train), color='gray', linestyle='--', label="Train-Test Split")
plt.legend()
plt.title("Test Data and Predictions Appended After Original Data")
plt.xlabel("Index")
plt.ylabel("Class Label")
plt.show()테스트 데이터 이후 30일 치 데이터를 예측한 뒤 시각화를 수행해보았습니다.
last_x_test = best_x_test[len(best_x_test)-1].reshape(1, best_x_test.shape[1], 1)
y_total = np.array([])
now = 0
for i in range(30):
now = best_model.predict(last_x_test)
last_x_test = np.append(last_x_test[len(last_x_test)-1][1:len(last_x_test[len(last_x_test)-1])], now).reshape(1, best_x_test.shape[1], 1)
y_total = np.append(y_total, now)
model_none_test_view(best_model, best_y_train, best_x_test, best_y_test, y_total)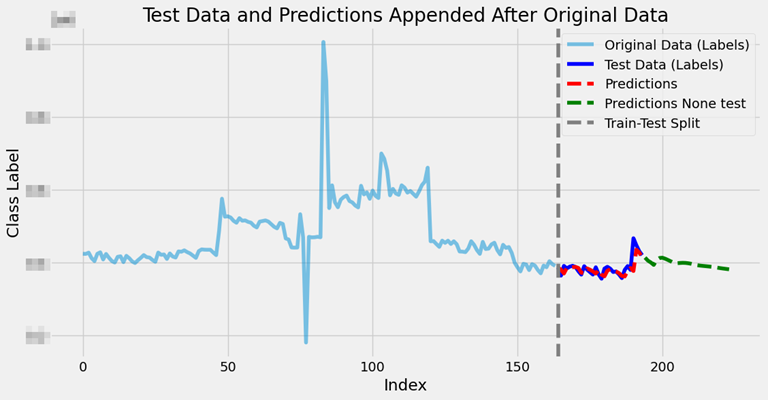
학습 데이터를 이용했을 때 예측되는지 확인을 위해 시각화 함수를 생성해보았습니다.
def model_all_test_view(model, x_train, y_train, x_test, y_test, y_none_test):
train_pred = model.predict(x_train)
y_pred = model.predict(x_test)
import matplotlib.pyplot as plt
original_range = range(len(y_train))
test_range = range(len(y_train), len(y_train) + len(y_test))
pred_range = range(len(y_train), len(y_train) + len(y_pred))
none_test_range = range(len(y_train) + len(y_pred), len(y_train) + len(y_pred) + len(y_none_test))
plt.figure(figsize=(12, 6))
plt.plot(original_range, y_train, label="Original Data (Labels)", alpha=0.5)
plt.plot(original_range, train_pred, label="Train Test", alpha=0.2)
plt.plot(test_range, y_test, label="Test Data (Labels)", color='blue')
plt.plot(pred_range, y_pred, label="Predictions", color='red', linestyle='dashed')
plt.plot(none_test_range, y_none_test, label="Predictions None test", color='green', linestyle='dashed')
plt.axvline(len(y_train), color='gray', linestyle='--', label="Train-Test Split")
plt.legend()
plt.title("Test Data and Predictions Appended After Original Data")
plt.xlabel("Index")
plt.ylabel("Class Label")
plt.show()새로 생성한 함수에 대해서도 예측해보았고 경향이 잘 반영된 것이 확인됩니다.
model_all_test_view(best_model, best_x_train, best_y_train, best_x_test, best_y_test, y_total)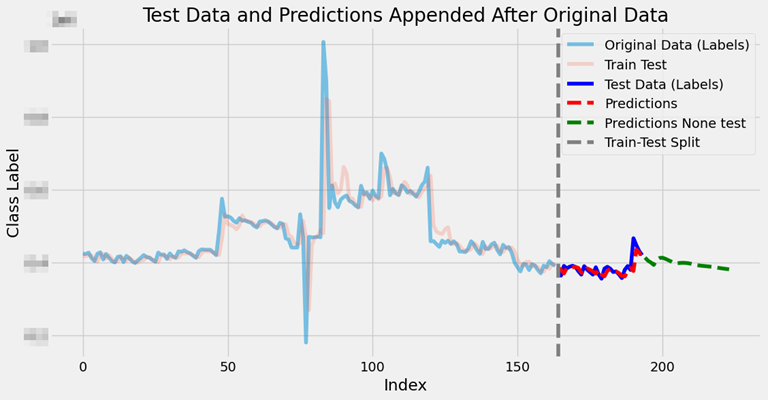
이렇게 최적의 모델을 만들고 이를 이용하는 방법에 대해 확인할 수 있었습니다.
📚 관련 코드
아직 코드에 대한 정리가 전체적으로 완료되지 않아 별도 업로드를 해두지 않았습니다.
추후 어느정도 정리되면 .ipynb 형태로 GitHub 저장소를 만들어 업로드 예정입니다.
😅 아쉬운 점
인공지능 알고리즘과 같은 요소에 대해 여러가지 공부를 많이 해보았다고 생각하였는데,LSTM에서의 추가 학습이라던가 시계열 데이터의 교차 검증에 대한 궁금증이 생깁니다.
현재 프로젝트는 해당 부분에 대한 의문만 제기됐고 실제로 학습하지는 못한 상태입니다.
추후에는 이러한 부분을 조금 더 연구하여 일반화된 모델을 만들고자 계획 중입니다.
😏 향후 계획
사용자 간 성향 차이가 있기에 데이터를 예측할 때 각자의 모델을 만들고자 했습니다.
다만, 이 과정에서 최적의 값을 찾는데에 너무 오랜 시간이 소요되는 문제가 있습니다.
(450개 경우의 수로 모델 제작, 비교 간 약 5시간 씩의 시간이 소요됐습니다.)
생각하고 있는 프로세스는 6개월 이상의 데이터 누적 시 모델을 생성하도록 유도하고,
생성된 모델을 이용해 매월 추가로 학습하여 모델의 크기를 늘려갈까 생각 중입니다.
여기서 Pre-Trained 모델 형태를 사용할 수도 있을 것인데, 이는 고민해볼 사항입니다.시계열 데이터 특성에 추가 학습이 문제가 없을지 등에 대한 고민도 많이되고 있습니다.
마지막으로 지금은 총 비용만 예측하지만, 각 상품 별 비용으로도 확장하고자 합니다.
새해 첫 날 첫 포스팅이네요! 다들 새해 복 많이 받으시고 즐거운 한 해 되세요!
정말 긴 포스팅 끝까지 읽어주셔서 감사드립니다. 😎