[Project] "식자재 관리의 새로운 방법을 만나다, 뉴밋" 프로젝트 회고
정보
📢 현재 포스팅은 2024년 1학기에 진행한 팀 프로젝트에 대한 회고입니다.
프로젝트의 전체 기한과 제가 수행한 인프라, 인공지능 파트를 소개합니다.
🎨 프로젝트 개요
보관 폐기, 먹지않은 음식물이 전체 버려지는 식자재 중 13%를 차지할 정도로
높은 비율을 차지하고 있고 식자재 관리에 어려움을 겪는 사용자가 굉장히 많습니다.
식자재가 잘 소비되어 낭비되지 않도록 하는 것을 목표로 프로젝트를 기획했고,
이를 위해 보관 위치나 소비 기한을 알려주거나 레시피를 제공하는 등의 기능으로
사용자가 식자재를 보다 쉽게 관리하고 이를 넘어 사용할 수 있는 방안을 제공합니다.
🧑💻 프로젝트 참여자
- 강찬 (
Product Manager)Image데이터 수집 및 가공Object Detection모델 학습LLM모델Prompt EngineeringCloud Infra아키텍처링 및 구축
팀원 및 프로젝트 일정 조율
서류 작성 및 제출 - 은영환 (
UI/UX Design & Publishing)UI/UX디자인 작성Publishing및UI구현
서류 작성 및 보완
프로젝트에 대한 추가 아이디어 제안 - 이재용 (
Back-End)Back-End및Web서비스 연동 개발SpringBoot기반 서비스 개발MySQL쿼리 설계 및 연동
🖼️ 아이디어 스케치
프로젝트 아이디어는 여러 가지가 존재하였고 최종 의견으로는 두 가지가 남았습니다.
의견은 아래 두 가지로 상세하진 않지만 간단한 아이디어로는 아래와 같게 구성됩니다.
🥘 식자재 관리 플랫폼
- 프로젝트 개요
- 식자재를 관리하는 플랫폼을 제공하여 식자재를 손쉽게 등록하고 이를 소비할 방법 제공
- 주요 기능
객체인식: 식자재 객체를 인식하고 구분하여 자동으로 내용을 저장- 냉장고: 자신만의 식자재 보관 그룹을 만들고 식자재에 대한 데이터 보관
- 레시피: 자신의 레시피를 다른 사용자와 공유하고 식자재 별 레시피를 추천
- 인공지능을 이용한 레시피 추천:
LLM을 이용한 창의적인 레시피를 추천
- 인공지능을 이용한 레시피 추천:
📜 뉴스 키워드 분석을 통한 실시간 순위
- 프로젝트 개요
- 뉴스의 주요 키워드를 분석하고 최근 화두가 되고 있는 키워드와 숨겨진 키워드를 발견
- 주요 기능
- 실시간 뉴스 키워드를
워드클라우드와 비슷한 형태로 제공 - 주요 키워드를 이용한 실시간 화제 정보를 정리하여 페이지로 제공
- 심각도가 높지만 실시간으로 화제가 되지 않고 있는 정보를 숨겨진 키워드로 제공
- 실시간 뉴스 키워드를
⌛ 개발 기간
프로젝트 참여 인원이 모두 재직자이자 학생으로 적은 시간으로 참여하게 됐으며,
실제 프로젝트 기한은 이보다 더 타이트하게 이뤄진 점 참고 부탁드리겠습니다.
- 총 기간: 2024.03.10 ~ 2024.06.04
- 계획 수립: 2024.03 ~ 2024.03
- UI/UX 개발/보완: 2024.04 ~ 2024.05
- 이미지 데이터 수집: 2024.03 ~ 2024.04
- 객체인식 모델 학습: 2024.04 ~ 2024.05
- 백엔드 서비스 개발: 2024.05 ~ 2024.06
- 프롬프트 엔지니어링: 2024.05 ~ 2024.06
- 최종 발표: 2024.06.08
💻 개발 스택
👔 UI/UX
✂️ 도구
🔧 언어
🦴 프레임워크
🔬 백엔드
✂️ 도구
🔧 언어
🦴 프레임워크
💺 인프라
🚌 플랫폼
🦾 OS
🚢 컨테이너
🫙 Database
🤖 인공지능
🔧 언어
🦴 프레임워크
✍️ LLM
🤔 구분 별 회고
😺 객체인식
객체인식은 주요 기능이고, 처음 다뤄보는 분야이기에 러닝 커브가 존재했습니다.
최근에는 YOLO를 이용한 학습 모델을 구현하는 것이 높은 인식률을 보여줍니다.
해당 프로젝트에서는 TensorFlow를 이용해 개념부터 이해하려고 노력했습니다.
YOLO의 경우 PyTorch를 기반으로 하기에 여기서는 모델 별 인식률을 확인하고
결과에 의거하여 최적의 모델을 확인한 뒤 모델 학습 및 Serving 하였습니다.
🔭 모델 선정
사전 학습 모델 선택을 위해 TensorFlow에서 제공 중인 Model zoo를 참고했습니다.
또한 가용할 수 있는 자원이 많지 않기에 모델은 CPU 가동이 가능한가도 평가했습니다.
이에 평가 기준은 적당한 학습 소요 시간과 점수, 동작 시간, CPU 동작 여부입니다.
| Index | Model name | Speed (ms) (A100 GPU 기준) | COCO mAP | 학습 소요 시간(Hour) (RTX4090 기준) | CPU 동작 여부 |
|---|---|---|---|---|---|
| 1 | SSD MobileNet V1 FPN 640x640 | 48 | 29.1 | 3.3 | 동작 |
| 2 | SSD MobileNet V2 FPNLite 320x320 | 22 | 22.2 | 1.4 | 동작 |
| 3 | SSD MobileNet V2 FPNLite 640x640 | 39 | 28.2 | 2.5 | 동작 |
| 4 | SSD ResNet50 V1 FPN 640x640 (RetinaNet50) | 46 | 34.3 | 9.3 | 일부 지연 |
| 5 | Faster R-CNN ResNet50 V1 640x640 | 53 | 29.3 | 7 | 자원 부족 |
표 상으로 가장 높은 성능을 보이는 것은 4번 모델이었지만 학습 소요 시간이 가장 길고,
모델의 리소스 사용량이 높아 CPU 환경에서 다소 지연되고 문제가 있는 모습을 보였습니다.
선정이 가능한 CPU에서 정상적으로 동작되는 경량화된 모델은 1, 2, 3번 모델이었고,
성능 기준으로 1번 모델, 학습 시간 기준으로는 2번 모델을 선택하는게 좋아보였습니다.
다만, 여러번 학습을 수행하여야 하기에 이에 중간 정도인 3번 모델을 대상 선정하였습니다.
📷 이미지 수집
이미지 수집은 모델이 내가 원하는 대상을 찾을 수 있도록 학습 시키기 위한 요소로
처음 데이터를 수집할 때는 Google 검색을 통해 데이터를 수집하여 보관하였습니다.
너무 고된 노역이라는 생각이 들어 Python을 이용한 자동화 스크립트를 작성하게 됐고,
아래와 같은 간단한 크롤링 스크립트를 통해 키워드 별 데이터를 수집할 수 있었습니다.
- 크롤링 함수 작성 (
Selenium이용)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
import urllib.request
import os
def crawlImages(search, count, saveurl):
download_list = []
service = Service(executable_path=r'<크롬 드라이버 경로>')
options = webdriver.ChromeOptions()
options.headless = True
options.add_argument("window-size=1920x1080")
options.add_argument("--no-sandbox")
options.add_argument("--headless")
options.add_argument("--single-process")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("incognito")
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&ogbl")
driver.save_screenshot(f"{search}q1.png")
elem = driver.find_element(By.NAME, "q")
elem.send_keys(search)
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
driver.save_screenshot(f"{search}q2.png")
if new_height == last_height:
try:
driver.find_element(By.CSS_SELECTOR, ".LZ4I").click()
except:
break
last_height = new_height
images = driver.find_elements(By.CSS_SELECTOR, ".Q4LuWd")
now_count = 1
i = 0
while True:
if len(images)-1 < i:
print(len(images), i)
print(search, "검색어에 대한 결과가 부족합니다.")
break
try:
images[i].click() # 이미지 클릭
time.sleep(1)
imgUrl = driver.find_element(By.CSS_SELECTOR, ".iPVvYb").get_attribute("src")
print(imgUrl)
if ".jpg" in imgUrl:
if imgUrl in download_list:
i += 1
continue
download_list.append(imgUrl)
urllib.request.urlretrieve(imgUrl, saveurl + str(now_count) + ".jpg") # 이미지 다운
now_count += 1
except:
pass
if now_count == count+1:
break
i += 1
with open(saveurl + "download_list.txt","w+") as f:
f.write('\n'.join(download_list))
driver.close()
import os.path
from os import path- 이미지 수집 및 저장
searchs = [
# [검색어, 개수, 저장 경로]
["채소", 100, ""],
]
for search in searchs:
if not path.exists(search[2]):
os.mkdir(search[2])
print(search[0], "시작")
crawlImages(search[0], search[1], search[2])이렇게 총 59가지의 종류의 라벨에 대한 2,082개의 이미지를 수집할 수 있었습니다.
🏷️ 이미지 라벨링
이미지 라벨링은 각 이미지 상 어떠한 부분을 무엇으로 구분할지 정답지를 주는 것으로,
수집된 이미지에 어떠한 항목이 어떤 것인지에 대해 확인 후 작성하는 것을 수행해야합니다.
이 부분은 자동화가 어렵기에 LabelImg를 이용하여 아래와 같이 라벨링했습니다.

🫠 모델 학습
이미지 라벨링을 통해 이미지를 수집했고 이를 이용하여 모델의 학습 수행을 하게 됐습니다.
학습은 Docker에 존재하는 TensorFlow에 대한 이미지를 활용하여 수행하게 됐으며,Windows 시스템 상에 WSL을 구성한 뒤 Ubuntu 상 Docker를 설치하였습니다.
당시 제 GPU와 호환되는 버전인 2.15.0.post1-gpu-jupyter 이미지를 이용하였습니다.
해당 이미지는 TensorFlow 뿐 아닌 NVIDIA Driver, Jupyter가 설치/제공됩니다.
이미지를 Pulling 하는 방법은 명령어 기준으로는 아래와 같이 진행할 수 있습니다.
$ docker pull tensorflow/tensorflow:2.15.0.post1-gpu-jupyterTensorFlow 이미지의 컨테이너 상 특정 경로를 매핑하여 파일을 읽을 수 있도록 했습니다.
또한 GPU를 할당 및 Notebook의 8888 포트와 TensorBoard의 6006 포트를 포워딩했습니다.
$ docker run --gpus all --name tf -p 8888:8888 -p 6006:6006 -v <경로>:/tf/ -d tensorflow/tensorflow:2.15.0.post1-gpu-jupyter모델 학습 간 사용할 이미지를 하나의 경로로 이동 및 Pascal VOC 기반의
내용 중 문제가 될 수 있는 path와 filename을 전처리로 수정하였습니다.
import shutil
fruits = []
now_index = 1
for forder in folder_list:
fruits.append(forder)
file_list = os.listdir(path + forder + "/")
for file in file_list:
if 'jpg' in file:
file0 = file.split('.')[0]
shutil.copy(path + forder + "/" + file0 + ".jpg", move_dir + str(now_index).zfill(8) + ".jpg")
new_text_content = ''
with open(path + forder + "/" + file0 + ".xml", 'r', encoding='utf-8') as f:
lines = f.readlines()
for i, l in enumerate(lines):
if i == 1:
new_string = '<folder></folder>'
elif i == 2:
new_string = f'<filename>{str(now_index).zfill(8)}.jpg</filename>'
elif i == 3:
new_string = f'<path>{str(now_index).zfill(8)}.jpg</path>'
elif i == 4:
new_string = '<source>'
else:
new_string = l.strip()
if new_string:
new_text_content += new_string + '\n'
else:
new_text_content += '\n'
with open(move_dir + str(now_index).zfill(8) + ".xml",'w') as f:
f.write(new_text_content)
now_index += 1한 경로로 모인 모든 데이터를 학습 데이터와 테스트 데이터로 분할했고
데이터가 약 8:2 비율로 분할되도록 확률적인 코드를 작성하여 분할했습니다.
아래 코드대로 실행 시에 파일의 개수가 항상 일정하게 분배되지는 않습니다.
추후에는 해당 코드 외 다른 코드 형태로 데이터를 분할하여 사용할까 합니다.
# TEST DATA
import random
test_dir = '../images/test/'
train_file_list = os.listdir(move_dir)
print(len(train_file_list)//2)
test_data = 2
for file in train_file_list:
if 'jpg' in file:
if 10-test_data < random.randrange(1,11) <= 10:
xml_file = file.split('.')[0] + ".xml"
shutil.move(move_dir+file, test_dir+file)
shutil.move(move_dir+xml_file, test_dir+xml_file)
print(file)모델 학습의 경우 TensorFlow 2 기반으로 이 게시물을 참고하여 구현하였습니다.
자세한 학습 내용은 추후 TensorFlow 2 기반 모델 학습 방법으로 찾아오겠습니다.
우선 여러 번의 학습을 반복했고 기본적으로 제공되는 사전 학습 모델의 기본 값인50,000 Epoch를 기준으로 점차 횟수를 줄이면서 학습 5회 정도 수행하였습니다.
학습 간 학습률과 손실에 대한 값을 TensorBoard에서 아래와 같이 확인 가능합니다.
(아래 값은 20,000 Epoch 실행 간 발생된 사항을 그래프로 기록한 사항입니다.)
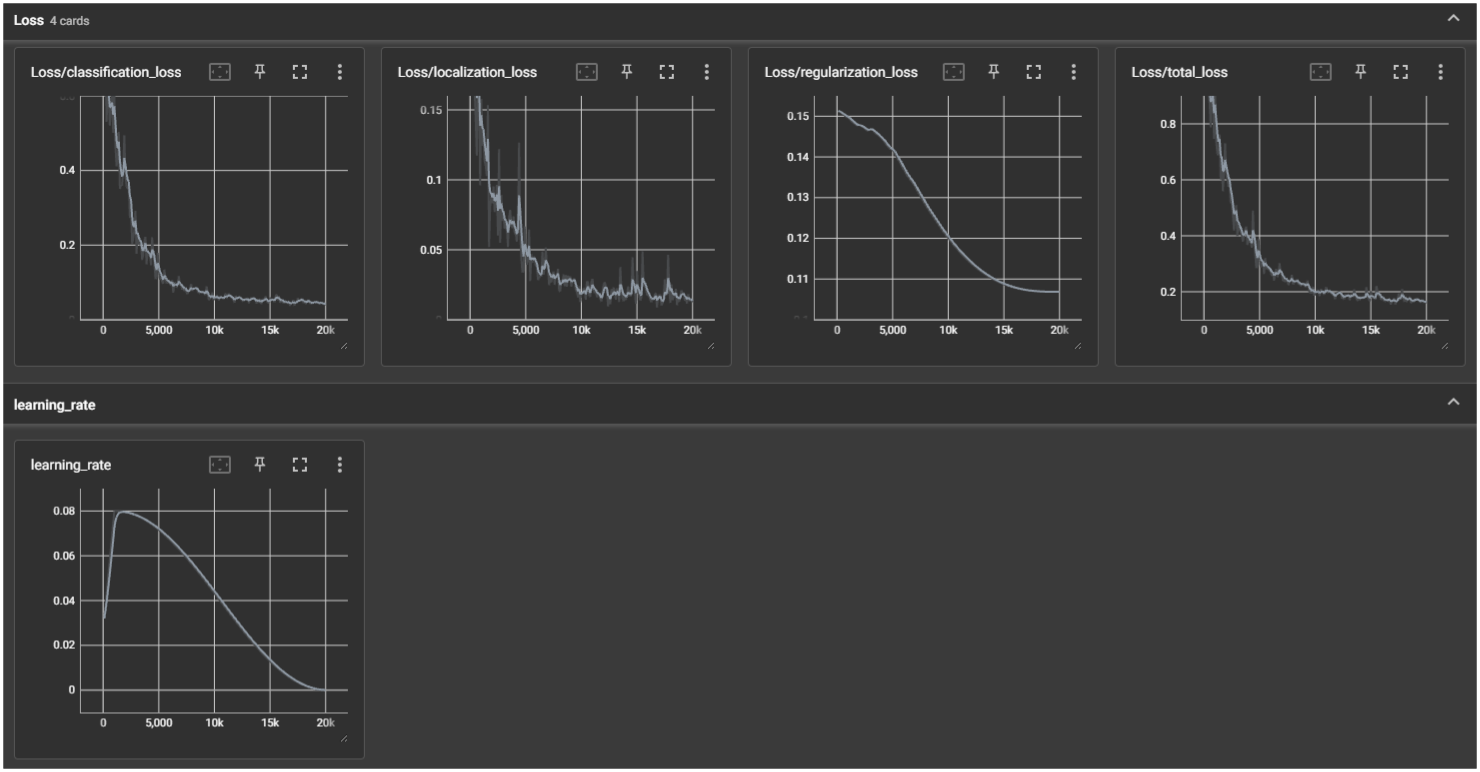
확인 시 학습 데이터 양이 작기 때문인지 과대적합으로 인해 높은 Epoch인 경우
분류를 잘못하는 것으로 보였고 10000~25000 Epoch가 성능이 괜찮았습니다.
(위 테스트 데이터는 별도 그래프로 저장하지 못하여 아쉬울 따름입니다..)

이에 따라 25,000 Epoch를 기준으로 모델을 제작하여 추출하였습니다.
추출은 학습된 Checkpoint 파일에 Export 스크립트를 실행하는 방법을 이용합니다.
추출된 모델 파일은 아래와 같은 파일 구조를 갖게 되므로 내용 참고 부탁드리겠습니다.
Model/
├─ checkpoint/
├─ saved_model/
│ ├─ checkpoint
│ ├─ ckpt-0.data-00000-of-00001
│ └─ ckpt-0.index
├─ pipeline.config
│ ├─ assets/
│ ├─ variables/
│ │ ├─ variables.data-00000-of-00001
│ │ └─ variables.index
│ ├─ fingerprint.pb
│ └─ saved_model.pb⏏️ 모델 추출 및 Serving
학습이 완료된 모델의 파일을 모두 추출하고 이를 외부에서 API 등의 형태로 호출이 필요했습니다.
이런 형태를 Model Serving이라 하고 TensorFlow는 대표적으로 2가지 방식이 있었습니다.
Django,Flask등 웹 프레임워크를 이용한 ServingTensorFlow Serving
두 가지 방식을 속도 등의 면에서 비교하였으며 이러한 비교 자료를 기반으로 선정을 하게 됐습니다.
| 항목 | Django | TensorFlow Serving |
|---|---|---|
| gRPC | 지원 불가 | 0.983s |
| HTTP | 9.088s | 1.624s |
우선 우리가 필요한 것은 REST API 형식의 HTTP 형태였고 이를 기준으로 비교 시
5배 이상의 시간 차이를 보여 성능, 기능 면 모두 TensorFlow Serving이 좋았습니다.
TensorFlow Serving를 선정하게 됐고 사용을 위해 컨테이너 기반으로 구축 했습니다.
인프라 환경 상 CPU 환경으로 Docker를 설치하여 컨테이너를 구축하였습니다.
$ docker pull tensorflow/serving:2.15.1컨테이너 상 특정 경로를 매핑하여 모델을 인식할 수 있도록 제공하였습니다.
$ docker run -d -i -t -p 8501:8501 -v "<모델경로>:/models/<모델명>" -e MODEL_NAME=<모델명> tensorflow/serving:2.15.1 --name tf_serving이후 아래와 같이 API를 호출하여 모델에 데이터를 입력 후 출력 데이터를 수신했습니다.
| 호출 주소 | Method | 내용 |
|---|---|---|
| http://localhost:8501/v1/models/<모델명>:predict | POST | {"instances": [이미지 픽셀 데이터] } |
출력 데이터는 아래와 같은 형식으로 제공되며 이중 필요한 데이터를 추출하여 사용합니다.
{
"predictions": [
{
"detection_multiclass_scores": [[]], // Detection에 대한 클래스 별 점수
"detection_classes": [1.0], // 어떤 항목이 Detection 됐는지
"detection_anchor_indices": [], // NMS라는 Bounding Box를 줄이는 작업 진행 후 Box
"detection_boxes": [[0.1, 0.1, 0.1, 0.1]], // 항목의 Box 위치
"detection_scores": [0.92344], // Detection된 항목의 점수
"raw_detection_boxes": [], // NMS 작업 진행 전 전체 Box
"num_detections": 100.0, // Detection된 개수
"raw_detection_scores": [] // NMS 작업 진행 전 점수
}
]
}위 API를 사용하는 방법에 대해서 개발자에게 전달하여 시스템과 연계할 수 있었습니다.
✍️ LLM
LLM은 기존의 계획에는 없었지만 내부적으로 논의 간 추가적인 기능이 고안되어 추가했습니다.
고안한 기능은 LLM 모델에서 사용자의 보유 식자재를 확인하고 레시피를 추천하는 기능입니다.
저희 인프라는 기술 스택에서 표현해둔 사항과 같이 네이버 클라우드를 사용하여 구현합니다.네이버 클라우드도 자체 모델을 이용하여 HyperClova X라는 서비스를 제공하고 있습니다.
저희는 HyperClova X 중 HCX-003 모델을 이용하여 서비스를 구현하게 됐습니다.
📖 기능 구현
레시피는 등록된 데이터 외 LLM에서 자체적으로 데이터를 생성하여 제공하도록 진행하였고,System Prompt를 통해 데이터의 형식을 제안하여 고안된 내용을 전달하도록 하였습니다.
작성한 System Prompt는 아래와 같으며 이를 통해 JSON 형식으로 출력 메시지를 수신합니다.
## 소개
요리 레시피를 알려주는 AI입니다.
요구사항에 맞춰 적절한 레시피를 추천합니다.
## 요구사항
ingredients에 명시된 재료가 최대한 포함되는 레시피를 추천해주세요.
except_recipe에 명시된 레시피는 제외하고 비슷하거나 유사한 레시피도 제외합니다.
## 제공되는 형식
재료와 추천 제외 요리는 아래와 같이 JSON 형식으로 제공됩니다.
{
"ingredients": ["양파", "파", "삼겹살"],
"except_recipe": ["양파 조림"]
}
## 제공하는 형식
위와 같은 형식으로 제공받을 경우 아래와 같이 JSON 형태로 답안을 제공해줍니다.
{
"recipe_name": "삼겹살 덮밥",
"recipe_ingredients": ["양파", "파", "삼겹살", "통깨", "쌀", "간장", "설탕", "맛술", "굴소스", "간장", "물엿", "다진마늘", "물", "생강가루", "후춧가루"],
"recipes": [
"양파는 얇게 채를 썬 후 찬물에 담갔다가 체에 밭쳐 물기를 빼고 쪽파는 송송 썰어주세요. 볼에 간장 소스 재료를 넣고 섞어주세요.",
"달군 팬에 삼겹살을 올려 앞뒤로 노릇하게 굽고 한입 크기로 썰어주세요.",
"팬에 삼겹살을 굽고 나온 기름을 닦아 낸 후 간장 소스를 넣고 중약불에서 윤기 나게 조려가며 익혀주세요.",
"그릇에 따뜻한 밥을 담은 후 채를 썬 양파를 올리고 삼겹살을 돌려 담아주세요. 삼겹살에 팬에 남은 소스를 얹은 후 실파와 통깨를 뿌려 맛있게 즐겨주세요. (기호에 따라 가운데 달걀노른자와 연겨자를 올려 드시면 더욱 맛있게 드실 수 있답니다.)"
]
}내용을 보면 알 수 있듯 ingredients를 통해 보유 중인 식자재를 제공하게 되고,
원하지 않는 레시피가 존재할 경우 execpt_recipe를 통해 내용을 전달하게 합니다.
이렇게 전달된 데이터를 토대로 레시피의 정보와 재료, 그리고 과정을 출력해주는 구조입니다.
데이터는 반정형 데이터 형식인 JSON으로 반환하도록 했고 아래와 같이 실제 반환됐습니다.
// 입력 데이터
{
"ingredients": ["스파게티면", "미트볼", "삼겹살", "양파"],
"except_recipe": []
}// 출력 데이터
{
"recipe_name": "미트볼 스파게티",
"recipe_ingredients": ["스파게티면", "돼지고기 다짐육", "소고기 다짐육", "양파", "빵가루", "우유", "달걀", "소금", "후춧가루", "올리브오일", "마늘", "토마토소스", "페페론치노", "모차렐라 치즈"],
"recipes": [
"먼저 미트볼을 만들어보겠습니다. 양파 1/4개는 잘게 다지고, 빵가루 2큰술과 우유 3큰술, 달걀 1/2개, 소금 약간, 후춧가루 약간을 넣어 끈기가 생길 때까지 치대어 주세요. 그리고 4등분하여 둥글납작하게 빚어 줍니다.",
"이제 면을 삶아볼까요? 끓는 물에 소금 1큰술을 넣고 스파게티면 200g을 8분간 삶아 건져내 주세요. 삶은 면은 올리브오일을 뿌려 버무려 놓습니다.",
"팬에 올리브오일을 두르고 다진 마늘 1큰술을 볶아 향을 내다가 토마토소스 1컵 반(400ml)을 붓고 페페론치노 5개를 손으로 부숴 넣습니다. 끓어오르면 미트볼을 넣어 굴려가며 6분간 끓여 익힙니다.",
"삶은 스파게티면을 넣고 버무리듯 볶다가 불을 끄고 모차렐라 치즈 1줌을 올려 뚜껑을 덮어 치즈가 녹을 때까지 둡니다. 파슬리 가루를 솔솔 뿌려 마무리 해주세요."
]
}내용을 보면 알 수 있듯 제법 괜찮은 내용을 전달하고 있는 것을 확인할 수 있습니다.LLM 모델을 서비스 호출할 수 있도록 호출 URL을 만들어 개발자에게 전달하였습니다.
💺 인프라 구축
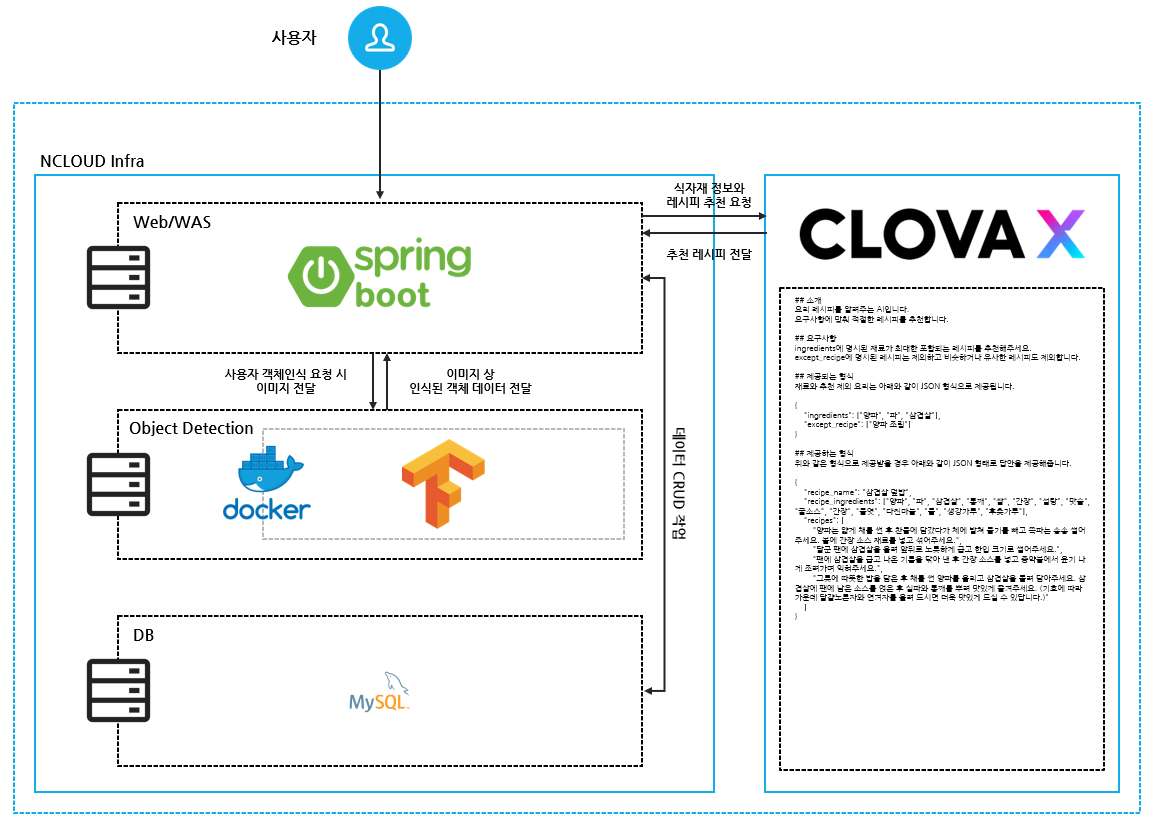
인프라는 비용적인 부담이 있기에 자체적으로 보유 중인 크레딧이 존재하여네이버 클라우드를 이용하였고 객체인식은 Docker로 배포하였습니다.
실질적으로 객체인식을 위해 올라간 이미지는 Serving 관련 이미지입니다.
이를 기반으로 서비스의 구성도를 작성할 경우 아래와 같은 형식으로 동작합니다.
😁 서비스 이미지
🤩 로그인 및 회원가입

🕵️ 메인 페이지 및 마이페이지
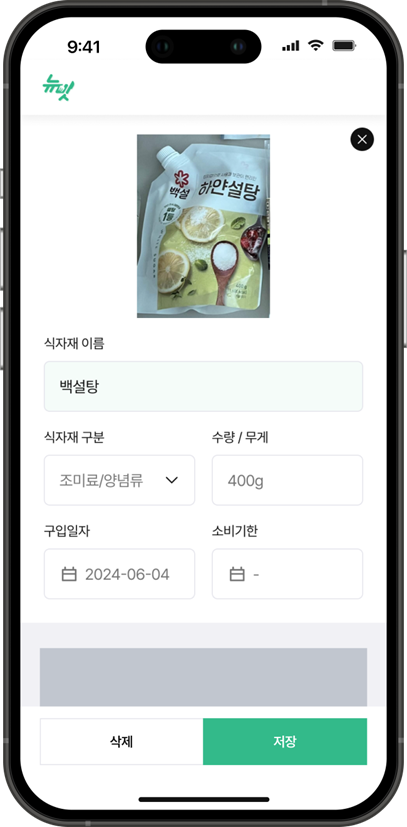
🧙 식자재 등록 페이지

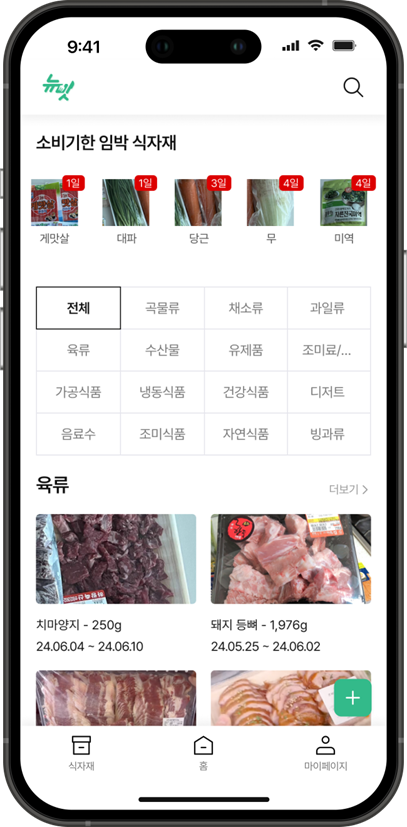
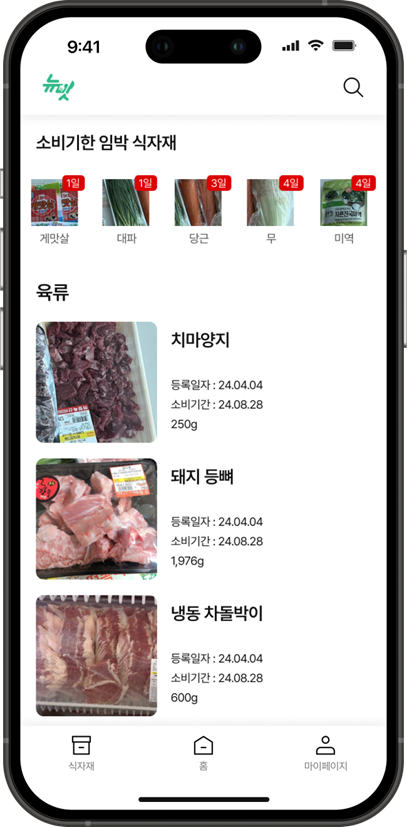
🎇 식자재 목록과 상세 확인 페이지
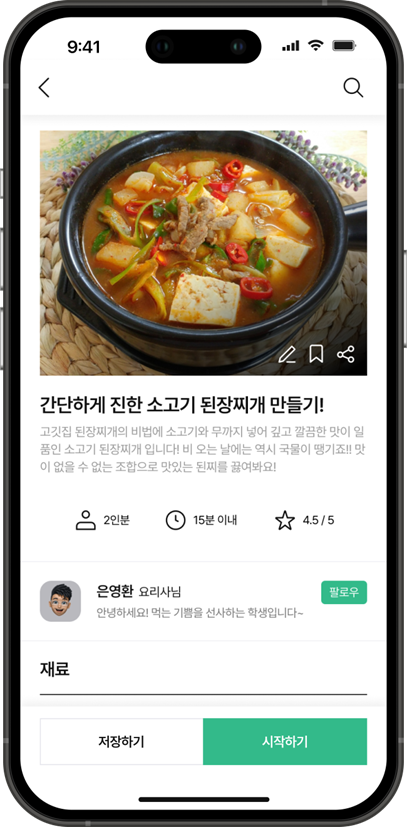
🧑🚀 등록된 레시피 확인 페이지
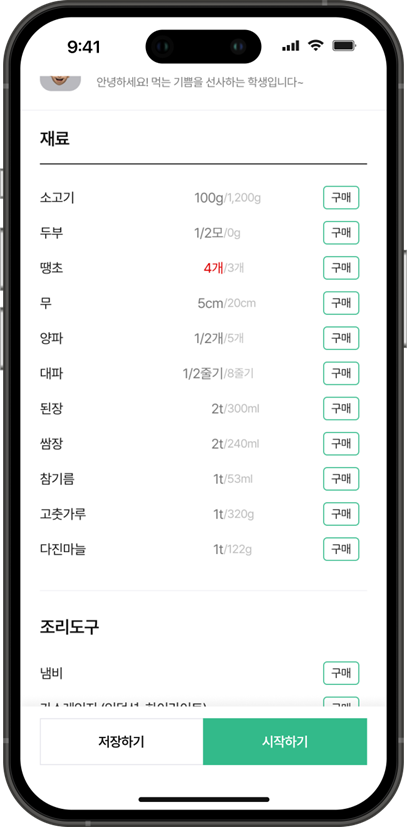
🍳 레시피 조리 확인 페이지
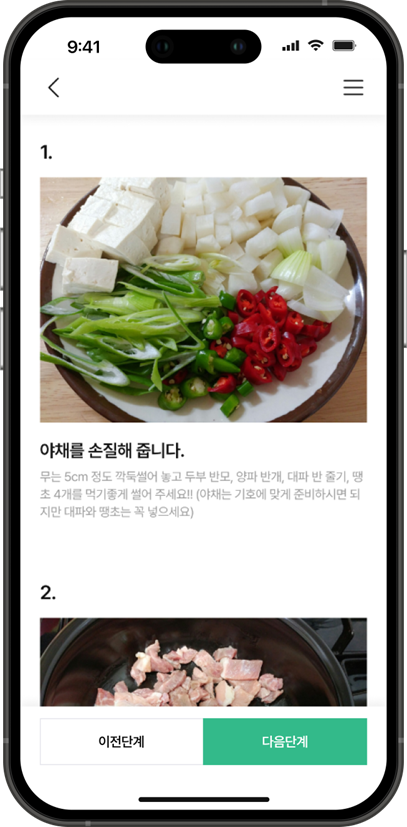
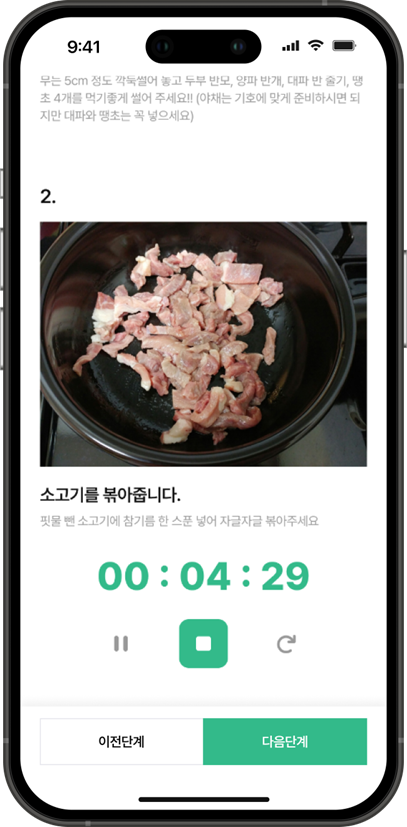
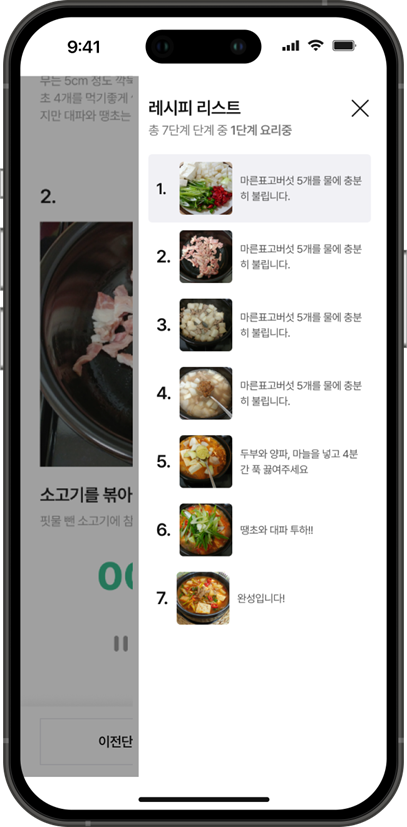
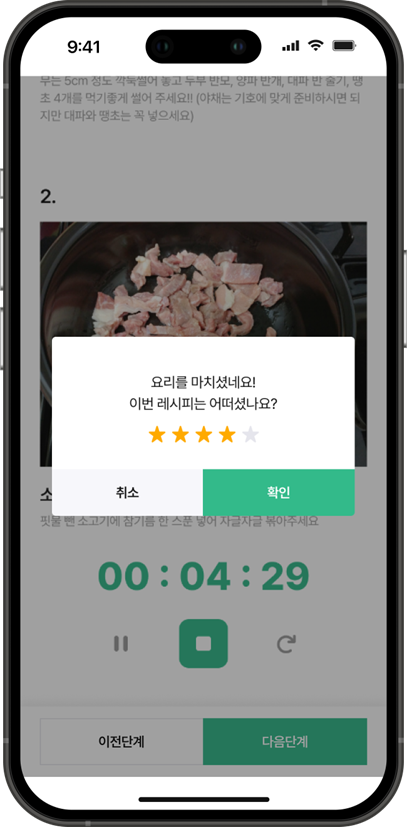
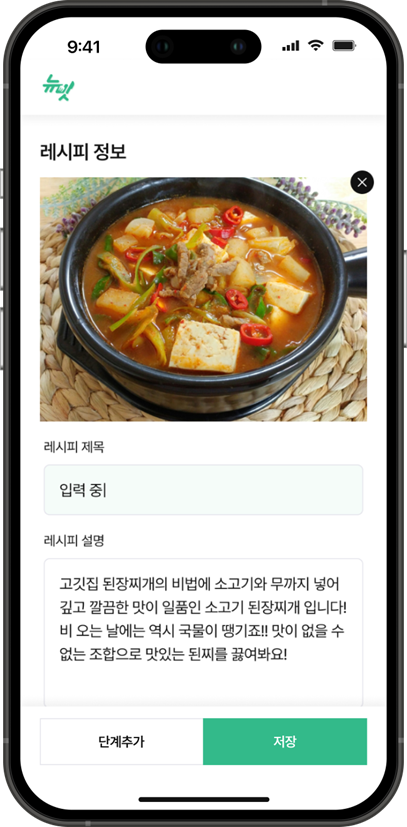
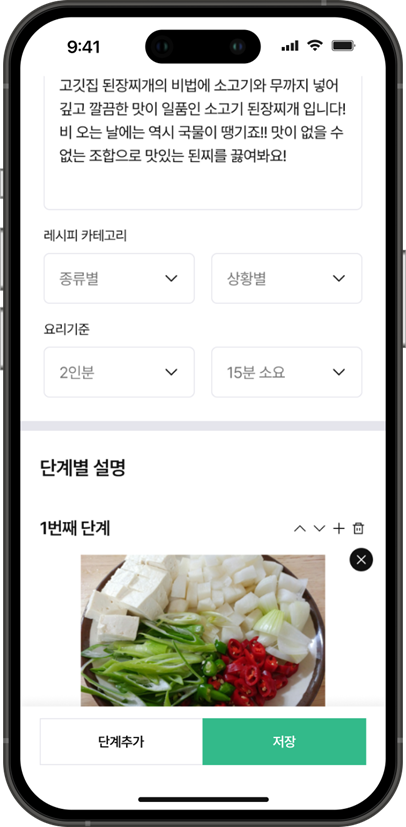
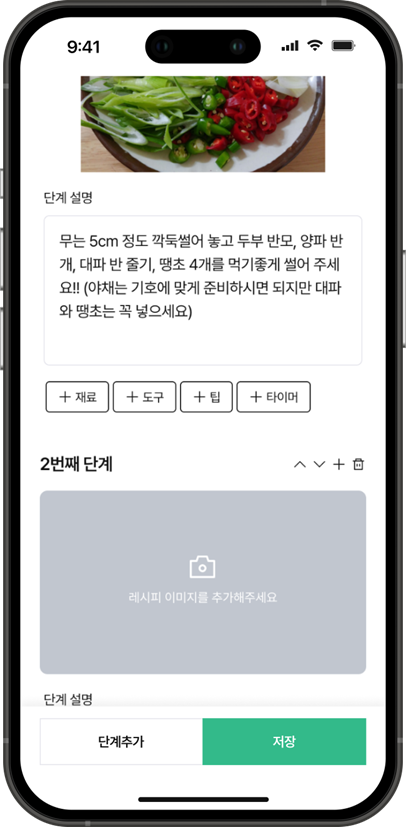
🍔 레시피 등록 페이지
✨ 인공지능 레시피 추천 페이지

📚 서비스 코드
서비스 코드는 전체는 아니지만 일부 내용에 대해 GitHub에 게시해둔 상태입니다.
HaeZuo / NewMit 저장소를 참고하시면 내용 확인이 가능하니 참고 부탁드립니다.
😅 아쉬운 점
😺 객체인식
모델 학습 과정에서 모델의 더 다양한파라미터를 조정해보지 못한 것이 아쉽습니다.
교차검증과 같은 방법을 통해 학습, 검증, 테스트 데이터를 나누지 못하여 성능 비교가 어려웠던 점,
학습 지표를 잘 활용하여 Epoch 별 학습률을 비교한 뒤 적정 학습률을 찾았으면 좋았을 걸 싶습니다.
다음에 진행할 땐 이러한 개념을 잘 활용하여 학습률 비교 지표 등을 만들어보는게 목표입니다.
✍️ LLM
LLM을 커스텀하여 이용한 것이 아닌 System Prompt만 이용하여 진행하게 됐습니다.
이에 따라 최신성도 떨어질 수 있기에 다음엔 RAG 등을 이용하는 것도 좋다고 생각합니다.
또한 현재는 HyperClova X와 같은 상용 모델을 사용하였지만 추후에는 모델을 바꾼다면,
자체 LLM을 만들 수 있도록 Meta LLaMa 3.1과 같은 오픈소스를 사용할까 고민 중입니다.
💺 인프라 구축
물론 실제 업무가 클라우드 서비스 관련 업무이기 때문에 실제로는 다양한 상품을 다루고 있지만,
비용적인 여건이 부족하기에 이번 프로젝트에선 제공되고 있는 다양한 상품을 사용하지 못했습니다.
추후에는 더 다양한 상품을 통해 간단한 서비스를 구축해보는 것도 하나의 경험일 것이라 생각됩니다.
😏 향후 계획
LLM을 이용한 레시피 추천 기능은 아쉽게도 실제 조리했던 내용에 대한 사진이 없습니다.Stable Diffusion과 같은 이미지 생성형 모델을 이용하여 사진을 생성할까 싶습니다.
이외 아쉽던 사항을 보완하고 더욱 편하게 개편하여 추후에 관련 개발 시 활용할 계획이 있습니다.
이번 프로젝트를 통해 더 인공지능에 대한 지식이 늘어난 것 같기도 하고,
4학년 2학기 딥러닝 수업을 통해 기본적인 구조와 이해도 진행 중입니다.
이제 졸업을 앞두고 있는데 대학원을 가려고 준비도 하고자 합니다.
이번 한해도 참 고민이 많고 여러가지로 생각이 많아지네요.
정말 긴 포스팅 끝까지 읽어주셔서 감사드립니다. 😎